Amazon S3 provides a cheap solution and easy to use solution to back up your Linux server or files on the cloud. The Linux s3cmd script lets you use rsync to backup folders and files easily, and you can even choose to just backup files that have changed since the last backup.
You need to start by installing s3cmd on your server. You can do this using apt-get (Ubuntu) or yum (Fedora or CentOS):
https://gist.github.com/5231858
Find your AWS Security Credentials
Next, you need to configure the application to use your AWS credentials. You can find your “Security Credentials” from the “My Account / Console” menu from the AWS site. Then, you need to run the s3cmd --configure command. You’ll be asked to enter your AWS Access and Secret keys so the script can access your S3 buckets.
Once configured, the script will verify your settings to confirm it can connect to your AWS account to access your S3 buckets. You can then list the buckets on your account by entering the command: s3cmd ls

You can then use the s3cmd sync to rsync files to your server. On my server, I use the following two commands to run the script from terminal or via a scheduled cron job:
https://gist.github.com/5231959
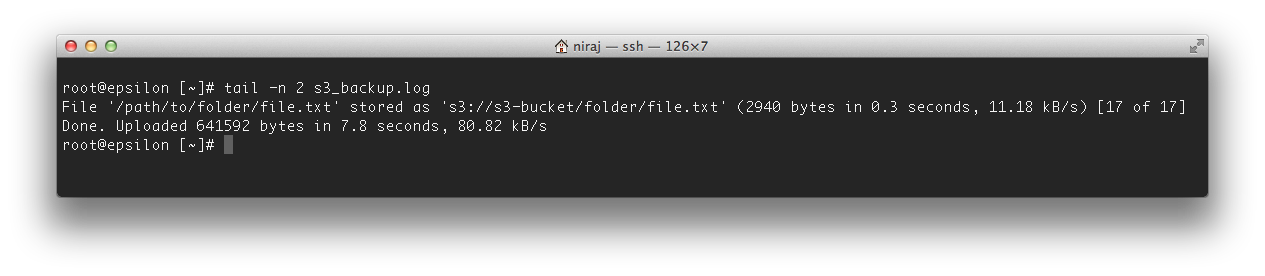
The above commands will log the results of the transfer to the s3_backup.log file. Looking at the last line of the file will reveal how many files were transferred, how long the transfer took and the size of the transfer: